
# 常用技法
# 推导式技巧
当你使用列表推导时,有几个技巧可以帮助提高代码的可读性和效率:
# 1. 使用条件表达式
可以在列表推导式中使用条件表达式,这样可以根据特定条件来筛选元素。
例子:将列表中的负数替换为0
numbers = [1, -2, 3, -4, 5]
new_numbers = [num if num >= 0 else 0 for num in numbers]
print(new_numbers)
# 2. 嵌套循环
你可以在列表推导中使用多个for循环,实现多层嵌套的迭代。
例子:生成一个二维数组
matrix = [[i * j for j in range(1, 4)] for i in range(1, 4)]
print(matrix)
# 3. 考虑生成器表达式
对于大型数据集,可以使用生成器表达式,它不会一次性生成所有结果,而是按需生成,节省内存。
# 列表推导式
list_result = [x * 2 for x in range(1000)]
# 生成器表达式
generator_result = (x * 2 for x in range(1000))
# 4. 避免过于复杂的推导式
有时候,过于复杂的列表推导式可能会降低代码的可读性。如果列表推导式太复杂,可以考虑使用普通的循环语句,使代码更易于理解和维护。
# 5. 注意可读性
确保推导式的结构清晰易懂,避免一行代码过长。合理使用缩进和空格来提高可读性。
列表推导式是Python中强大且常用的工具,但在使用时也要考虑代码的可读性和维护性。
# Python中,列表推导,求奇偶数
# 求奇数:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 使用列表推导筛选出奇数
odd_numbers = [num for num in numbers if num % 2 != 0]
print(odd_numbers)
这段代码会创建一个新的列表 odd_numbers,其中包含了 numbers 列表中的所有奇数。它通过遍历原始列表并使用条件判断来筛选出符合条件的元素。
# 求偶数:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 使用列表推导筛选出偶数
even_numbers = [num for num in numbers if num % 2 == 0]
print(even_numbers)
这段代码类似地创建了一个新列表 even_numbers,其中包含了 numbers 列表中的所有偶数。只是这次,条件判断的是数字是否能被2整除。
# Python:字符串内单词统计
import re
def count_words(sentence):
# 将句子转换为小写,以便不区分大小写
sentence = sentence.lower()
# 使用空格分割句子成单词列表,并去除标点符号
words = re.findall(r'\b\w+\b', sentence)
# 创建一个空字典来存储单词及其出现次数
word_count = {}
# 遍历单词列表并统计单词出现次数
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
return word_count
# 测试
sentence = "hello world,nice to meet you,哈哈,哈哈"
result = count_words(sentence)
print(result)

补充:
解释一下这个正则表达式 \b\w+\b:
\b匹配单词的边界,确保我们只匹配整个单词而不是单词的一部分。\w+匹配一个或多个字母、数字或下划线字符,即匹配一个单词。\b再次匹配单词的边界,确保单词结束。
# Python:删除列表中的重复值
要删除列表中的重复值,你可以使用几种方法来实现:
# 1. 使用 set(无序不重复集合):
将列表转换为集合,然后再转换回列表。集合中不允许有重复元素,这样就能够去除列表中的重复值。
my_list = [1, 2, 2, 3, 4, 4, 5]
# 使用set去除重复值,再转换回列表
my_list = list(set(my_list))
print(my_list)
但是需要注意的是,这种方法可能会改变原始列表中元素的顺序,因为集合是无序的数据结构。
# 2. 使用循环和新列表:
遍历原始列表,将不重复的元素添加到一个新的列表中。
my_list = [1, 2, 2, 3, 4, 4, 5]
new_list = []
for item in my_list:
if item not in new_list:
new_list.append(item)
print(new_list)
这种方法能够保留原始列表中元素的顺序,但在大型列表上可能会比较耗时。
# 3. 使用列表推导式和 not in 判断:
my_list = [1, 2, 2, 3, 4, 4, 5]
# 列表推导式去除重复值
my_list = [x for i, x in enumerate(my_list) if my_list.index(x) == i]
print(my_list)
这种方法也能保留原始列表中元素的顺序,但同样需要遍历列表来比较索引,对于大型列表可能效率不高。
选择合适的方法取决于你的需求,如果不关心顺序,使用集合可能是更简单的选择。如果需要保留顺序,可以选择其他方法来去除重复值。
# Python:如何字符串转整数
在 Python 中,你可以使用 int() 函数将字符串转换为整数。这个函数可以处理包含整数表示的字符串,并将其转换为对应的整数形式。
my_string = "1234"
# 将字符串转换为整数
my_integer = int(my_string)
print(my_integer)
在这个例子中,int() 函数将字符串 "1234" 转换为整数 1234。如果字符串包含非整数字符或者格式不符合整数表示,int() 函数可能会抛出 ValueError 异常。例如:
my_string = "123abc"
# 尝试将不符合整数格式的字符串转换为整数
try:
my_integer = int(my_string)
print(my_integer)
except ValueError as e:
print("转换失败:", e)
这段代码尝试将字符串 "123abc" 转换为整数,由于字符串中包含非整数字符,会抛出 ValueError 异常。
另外,int() 函数还可以接受第二个参数,用于指定进制。例如,如果你有一个十六进制的字符串,可以通过指定进制将其转换为整数:
my_hex_string = "1A"
# 将十六进制字符串转换为整数
my_integer = int(my_hex_string, 16)
print(my_integer) # 输出结果为26
这个例子中,int() 函数通过第二个参数 16 将十六进制字符串 "1A" 转换为对应的十进制整数 26。
# Python:字符串转列表
要将一个字符串转换为列表,可以使用字符串的 split() 方法。split() 方法根据指定的分隔符将字符串分割成子串,并将这些子串组成列表。
假设有一个用空格分隔的字符串,我们想要将其转换为一个单词列表:
my_string = "Hello world this is a string"
# 使用空格分割字符串,并转换为列表
my_list = my_string.split()
print(my_list)
在这个例子中,split() 方法默认使用空格作为分隔符,将字符串分割成单词,并将单词组成一个列表。结果会是:
['Hello', 'world', 'this', 'is', 'a', 'string']
你也可以使用其他分隔符来将字符串分割为列表,只需在 split() 方法中传入相应的分隔符作为参数:
my_string = "apple,orange,banana,grape"
# 使用逗号分隔字符串,并转换为列表
my_list = my_string.split(',')
print(my_list)
这段代码将会输出一个以逗号分隔的字符串转换为列表:
['apple', 'orange', 'banana', 'grape']
通过 split() 方法,你可以根据需要使用不同的分隔符将字符串分割成列表。
# Python:正则的贪婪匹配
贪婪匹配是正则表达式中的一种匹配模式,它尽可能多地匹配输入文本。在贪婪模式下,匹配的字符会尽量多地匹配满足模式要求的部分。
举个例子来说明:
假设有一个字符串 text = "abcdefg",我们想要用正则表达式匹配出 "abc" 和 "def" 之间的内容。
使用贪婪匹配的方式:
import re
text = "abcdefg"
pattern = "abc.*def"
result = re.search(pattern, text)
print(result.group(0))
这个正则表达式 abc.*def 中的 .* 表示匹配任意字符任意次数(包括零次),直到碰到字符 def。在贪婪模式下,它会尽可能多地匹配字符。因此,整个字符串 "abcdefg" 都满足这个模式,最终的匹配结果是整个字符串 "abcdefg"。
现在,如果我们想要非贪婪地匹配尽可能少的字符,只匹配到第一个 "def" 前的内容,可以这样改写正则表达式:
pattern = "abc.*?def"
这个正则表达式 abc.*?def 中的 .*? 表示非贪婪模式下的任意字符匹配。它会在尽可能少地匹配字符的情况下满足模式要求。在这个例子中,结果会是 "abcdef",因为它匹配了尽可能少的字符来满足模式要求,直到第一个 "def"。
# 总结Python中with方法有哪些作用
with语句在 Python 中有多种用途,主要用于创建上下文环境,在进入和离开代码块时执行特定的操作。最常见的用途之一是在文件处理中自动关闭文件,但它还可以用于其他需要资源管理的情况。
# 1. 文件操作
在文件操作中,使用 with 语句可以确保文件在使用完毕后被正确关闭,无需手动调用 file.close() 方法。
with open('file.txt', 'r') as file:
data = file.read()
# 在这里进行文件操作
# 文件在代码块结束后自动关闭,释放文件资源
# 2. 资源管理
with 语句还可以用于管理其他资源,比如网络连接、数据库连接或者其他需要手动打开和关闭的资源。这确保了资源在使用完毕后能够被及时释放,避免资源泄漏。
# 自定义资源
class Demo:
def __enter__(self):
print('初始化')
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print('资源清理')
with Demo() as demo:
print('资源正在使用中')
# 代码结束后,资源会自动被清理
注意:无论代码块是否发生异常,__exit__ 方法都会被调用,确保资源得到释放。
# 3. 上下文管理器
with 语句可以与实现了上下文管理器协议(Context Manager Protocol)的对象一起使用。这些对象包含 __enter__ 和 __exit__ 方法,它们定义了进入和退出上下文环境时的行为。
举例:
import time
class Timer:
def __enter__(self):
self.start_time = time.time()
return self
def __exit__(self, exc_type, exc_value, traceback):
self.end_time = time.time()
elapsed_time = self.end_time - self.start_time
print(f"代码块运行时间: {elapsed_time} 秒")
# 使用上下文管理器计算代码块的运行时间
with Timer():
# 在这里进行一些耗时的操作
time.sleep(2)
你也可以自定义一个上下文管理器,使用 with 语句来管理对象的生命周期,确保在进入和离开代码块时执行特定操作。
# 4. 锁和线程同步
在多线程编程中,with 语句可以用于管理锁或其他线程同步机制。例如,Python 中的 threading.Lock 对象可以通过 with 语句来管理线程间的互斥访问。
举例如下:
使用 Python 的 threading 模块创建了两个线程,它们共享一个公共的变量,并使用锁确保对该变量的安全访问:
import threading
# 公共变量
shared_variable = 0
lock = threading.Lock()
def increment():
global shared_variable
for _ in range(100000):
with lock:
shared_variable += 1
def decrement():
global shared_variable
for _ in range(100000):
with lock:
shared_variable -= 1
# 创建两个线程
thread1 = threading.Thread(target=increment)
thread2 = threading.Thread(target=decrement)
# 启动线程
thread1.start()
thread2.start()
# 等待线程执行结束
thread1.join()
thread2.join()
# 输出最终的共享变量值
print("共享变量的值:", shared_variable)
在这个例子中,increment() 和 decrement() 函数分别对共享变量进行增加和减少操作。threading.Lock() 创建了一个锁对象,用于确保在修改共享变量时线程间的安全访问。
with lock: 语句块确保每个线程在进入临界区(修改共享变量)之前会先获得锁,在离开临界区之后会自动释放锁。这样就能够确保同一时刻只有一个线程可以修改共享变量,避免了竞态条件(Race Condition)的发生。
总的来说,
with语句提供了一种简洁、可读性强且安全的方式来管理资源,确保资源在合适的时候被正确释放,是 Python 中良好的资源管理工具。
# 简析range和xrange的区别
在 Python 2 中,存在
range()和xrange()两个函数,但在 Python 3 中,xrange()已经被移除,只剩下了range()函数。
主要区别在于它们返回的对象类型不同:
range() 返回的是一个列表对象,它直接生成一个包含指定范围内所有元素的列表。在 Python 2 中,range() 会一次性生成整个列表,并将其存储在内存中。
my_range = range(5)
print(list(my_range)) # 在 Python 2 中直接打印 my_range 也会显示列表,[0, 1, 2, 3, 4, 5]
xrange() 返回的是一个生成器对象,它以一种惰性的方式逐个生成范围内的元素。在 Python 2 中,xrange() 是一个在迭代中逐步产生值的对象。
my_xrange = xrange(5) # 在 Python 2 中使用 xrange
for i in my_xrange:
print(i)
#0
#1
#2
#3
#4
#5
在 Python 3 中,range() 函数类似于 Python 2 中的 xrange(),它返回的也是一个惰性对象。这种改变的目的在于节省内存,特别是当范围非常大的时候,直接生成一个列表可能会占用大量内存,而惰性对象只在需要时逐个生成值,节省了内存空间。
因此,在 Python 3 中,你只需要使用 range() 即可,它返回的是一个惰性对象,可以在循环中逐步生成值,而不需要担心内存占用过大的问题。
# Python中zip()函数用法解析
摘要:zip()函数是 Python 中一个非常有用的函数,可应用于列表打包,列表解压,转置矩阵,列表合并等,本文展开解析并附上实例演示。
# 打包
zip() 函数是 Python 中一个非常有用的函数,它用于将多个可迭代对象组合成一个元组序列,依次将来自每个可迭代对象的元素打包在一起。
基本的语法是 zip(iterable1, iterable2, ...),其中 iterable1, iterable2, ... 是要合并的可迭代对象。
举例:
list1 = [1, 2, 3, 4, 5]
list2 = ['a', 'b', 'c', 'd', 'e']
# 使用zip函数将两个列表合并
zipped = zip(list1, list2)
# 查看合并后的结果
print(list(zipped))
这段代码将会输出:

zip() 函数将两个列表中对应位置的元素依次打包成元组,并将这些元组组合成一个迭代器。需要注意的是,zip() 会以最短的可迭代对象为准,如果有一个可迭代对象比其他的要短,那么 zip() 函数会在最短的可迭代对象耗尽时停止。
注意:如果你需要以较长的对象为基准进行配对,可以使用itertools.zip_longest()函数。
# 解压
你还可以用 zip() 函数进行解压,将打包的元组序列重新拆分成原始的多个序列:
pairs = [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd'), (5, 'e')]
# 使用zip函数进行解压
unzipped = zip(*pairs)
# 获取解压后的序列
unzipped_list1, unzipped_list2 = list(unzipped)
print(unzipped_list1)
print(unzipped_list2)
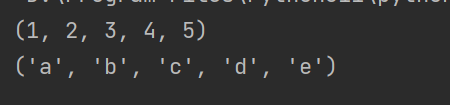
这样就能够将原先合并的元组序列重新分解为原始的列表。
# 转置矩阵
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
# 使用zip函数转置矩阵
transposed = list(zip(*matrix))
print(transposed)
这个例子中,zip(*matrix)会将原始矩阵转置,将原本行向量的列表转换为列向量的列表。如下:

# 字典合并
keys = ['a', 'b', 'c']
values = [1, 2, 3]
# 合并字典
my_dict = dict(zip(keys, values))
print(my_dict)

以上是一些关于zip函数的常用技巧,熟练掌握,有助于我们更巧妙解决开发中的问题和提高效率。
# Python生成随机数技巧
在Python中生成随机数有几种方式,其中常用的方式包括使用
random模块、numpy库以及secrets模块。这里给你举例说明一下:
# random模块
import random
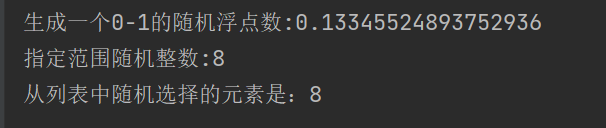
random_float=random.random()
print(f'生成一个0-1的随机浮点数:{random_float}')
random_int=random.randint(1,10)
print(f'指定范围随机整数:{random_int}')
my_list=[1,2,3,4,5,6,7,8,9]
print(f'从列表中随机选择的元素是:{random.choice(my_list)}')
# numpy库
import numpy
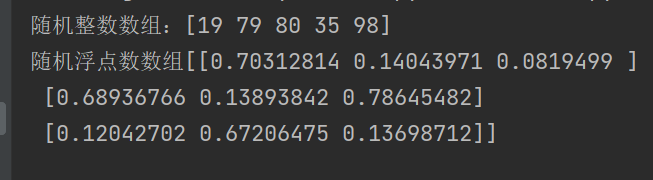
random_int_array = numpy.random.randint(1,100,size=5)
print(f'随机整数数组:{random_int_array}')
random_float_array = numpy.random.rand(3,3)
print(f'随机浮点数数组{random_float_array}')
# secrets模块
适用于需要更安全的随机数,比如密码学应用:
import secrets
# 生成一个安全的随机字节序列(可以用于生成密码等敏感信息)
random_bytes = secrets.token_bytes(16) # 生成16字节的随机字节序列
print(f'随机字节序列:{random_bytes}')
print(f'安全随机整数:{secrets.randbelow(100)}') # 生成0到99之间的随机整数

以上这些方法可以根据需要生成不同类型的随机数,并且可以通过设置范围、数组大小等参数来控制生成的随机数。
# 数组切片
在 Python 中,有多种方式可以去除数组(列表)中的第一个元素。以下是其中几种方法:
使用切片。你可以使用切片来获取从第二个元素开始到末尾的所有元素。例如:
python
my_list = [1, 2, 3, 4, 5]
my_list = my_list[1:] # 去除第一个元素
print(my_list) # 输出 [2, 3, 4, 5]
使用
del语句。你可以使用del语句来删除指定索引位置上的元素。例如:
my_list = [1, 2, 3, 4, 5]
del my_list[0] # 删除第一个元素
print(my_list) # 输出 [2, 3, 4, 5]
使用
pop()方法。你可以使用pop()方法来删除指定索引位置上的元素,并返回被删除的元素。例如:
python
my_list = [1, 2, 3, 4, 5]
my_list.pop(0) # 删除第一个元素
print(my_list) # 输出 [2, 3, 4, 5]
需要注意的是,以上方法都会改变原始数组(列表),如果你需要保留原始数组,可以先将其复制一份再进行操作。例如:
python
my_list = [1, 2, 3, 4, 5]
new_list = my_list[1:] # 复制一份并去除第一个元素
print(new_list) # 输出 [2, 3, 4, 5]
print(my_list) # 原始数组 [1, 2, 3, 4, 5] 未改变
# Python中控制台如何展示进度条——tqdm库使用
csdn

在 Python 中可以使用特定的库来创建控制台进度条,其中
tqdm是一个常用的选择,它能够方便地显示进度条并跟踪迭代的进度。你可以通过pip安装tqdm库:
pip install tqdm
# 包装迭代器:
使用 tqdm 来包装你的迭代器,比如 range() 函数或者列表。例如:
from tqdm import tqdm
import time
# 假设有一个很长的迭代过程
for i in tqdm(range(100)):
# 在这里执行迭代的任务
# 这里使用 time.sleep 模拟任务执行的时间
time.sleep(0.1)

# 手动更新进度条:
在某些情况下,你可能想手动更新进度条而不是使用迭代器。你可以使用 tqdm.update() 方法来手动更新进度。示例:
from tqdm import tqdm
import time
progress_bar = tqdm(total=1000)
for i in range(100):
# 执行任务
time.sleep(0.1)
progress_bar.update(10) # 手动更新进度条
progress_bar.close()

# 自定义外观和信息:
tqdm 允许你自定义进度条的外观和显示信息,比如设置进度条的描述、单位、动画样式等。例如:
from tqdm import tqdm
import time
for i in tqdm(range(100), desc='Processing', unit='iterations', ncols=100):
# 执行任务
time.sleep(0.1)

# 嵌套进度条:
如果你有嵌套的循环或任务,你可以使用 tqdm 的嵌套方式来显示多个进度条。示例:
from tqdm import tqdm
import time
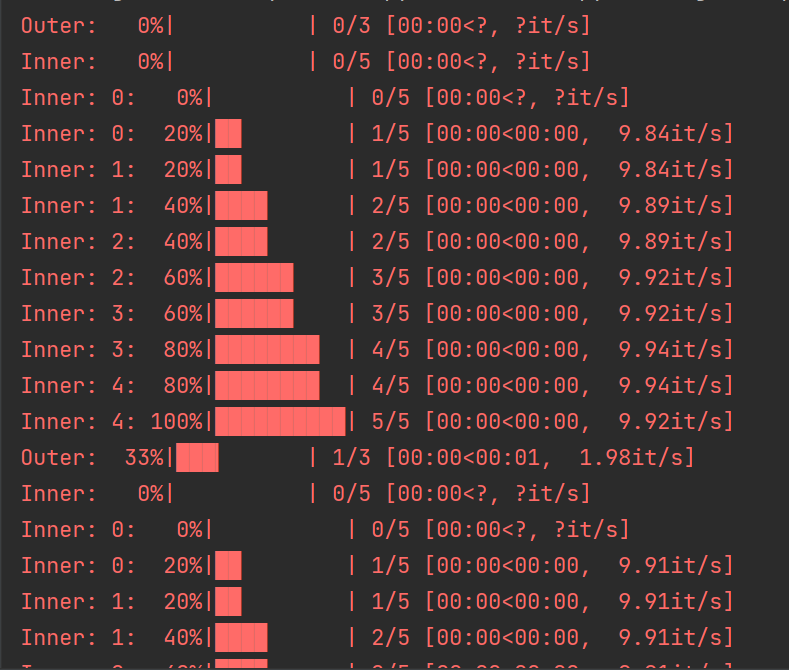
outer = tqdm(range(3), desc='Outer')
for i in outer:
inner = tqdm(range(5), desc='Inner', leave=False) # 内部循环不会覆盖外部进度条
for j in inner:
# 执行任务
time.sleep(0.1)
inner.set_description(f'Inner: {j}', refresh=True) # 更新内部进度条的描述信息
inner.close()
outer.update(1)
outer.close()
# 暂停和恢复:
tqdm 也允许你暂停和恢复进度条的更新。你可以使用 tqdm.pause() 和 tqdm.resume() 方法来暂停和恢复更新。示例:
from tqdm import tqdm
import time
progress_bar = tqdm(range(100))
for i in range(50):
time.sleep(0.1)
if i == 25:
progress_bar.pause() # 暂停更新
time.sleep(2) # 模拟一些耗时操作
progress_bar.resume() # 恢复更新
progress_bar.update(1)
progress_bar.close()
# window文件夹下python脚本实现批量删除无法预览的图片
csdn

有几种原因可能导致一些图片在预览时无法正常显示:
- 损坏的图片文件: 图片文件可能损坏或者部分损坏,导致无法被正常解析和预览。这种情况可能是因为文件在传输过程中损坏、存储介质出现问题或者文件本身存在错误。
- 不受支持的图片格式: 部分图片格式可能不受预览软件或系统所支持,因此无法在普通的图片预览软件中打开或显示。有些特殊的或者较为罕见的图片格式可能会遇到这个问题。
- 文件扩展名与实际格式不符: 有时文件扩展名可能与实际的文件格式不匹配,这可能导致操作系统或预览软件错误地尝试解析该文件。
- 图片文件损坏或缺失元数据: 图片文件损坏或缺少必要的元数据信息,可能导致预览软件无法正确识别或解析图片。
如何实现批量删除无法预览的图片呢?
import os
from PIL import Image
def is_image_valid(file_path):
try:
# 尝试打开给定路径的图像文件
Image.open(file_path)
# 如果能够正常打开,表示文件是有效的图片文件,返回 True
return True
except (IOError, SyntaxError):
# 如果打开文件时出现 IOError 或 SyntaxError,表示文件不是有效的图片文件,返回 False
return False
def delete_invalid_images(folder_path):
# 遍历指定文件夹中的文件
for filename in os.listdir(folder_path):
# 拼接文件路径
file_path = os.path.join(folder_path, filename)
# 检查路径是否是文件并且不是有效的图片文件
if os.path.isfile(file_path) and not is_image_valid(file_path):
# 删除无效的图片文件
os.remove(file_path)
# 输出被删除的文件路径
print(f"Deleted: {file_path}")
if __name__ == "__main__":
folder_path = r'G:\pythonProject\图\img' # 替换成你的图片文件夹路径
delete_invalid_images(folder_path)
效果如下:
# Python-csv库进行数据保存和读写
在 Python 中使用 CSV 文件非常简单,Python 提供了内置的 csv 模块来处理 CSV 文件。你可以使用 csv 模块来读取、写入和操作 CSV 文件中的数据。
# 基础使用
# 读取
python
import csv
# 打开 CSV 文件进行读取
with open('file.csv', mode='r') as file:
reader = csv.reader(file) # 创建 CSV 读取器对象
for row in reader:
print(row) # 逐行打印 CSV 文件中的数据
# 写入
python
import csv
# 写入数据到 CSV 文件
data = [
['Name', 'Age', 'Gender'],
['Alice', 25, 'Female'],
['Bob', 28, 'Male'],
['Cathy', 22, 'Female']
]
with open('output.csv', mode='w', newline='') as file:
writer = csv.writer(file) # 创建 CSV 写入器对象
writer.writerows(data) # 将数据写入到 CSV 文件
在这两个示例中,首先需要导入 csv 模块。使用 with open() 打开 CSV 文件并指定文件模式('r' 表示读取,'w' 表示写入)。然后使用 csv.reader() 或 csv.writer() 创建读取器或写入器对象。读取器可以逐行读取 CSV 文件的内容,写入器可以将数据写入到 CSV 文件中。
# 其他使用技巧
# 1. 处理不同格式的分隔符
有时 CSV 文件中的字段可能不是用逗号分隔的,可能会使用其他字符作为分隔符,比如制表符 \t。你可以在读取和写入时指定不同的分隔符。
读取不同分隔符的 CSV 文件:
# 使用制表符作为分隔符读取 CSV 文件
with open('file.tsv', mode='r') as file:
reader = csv.reader(file, delimiter='\t') # 指定分隔符为制表符
for row in reader:
print(row)
写入不同分隔符的 CSV 文件:
# 使用分号作为分隔符写入 CSV 文件
data = [
['Name', 'Age', 'Gender'],
['Alice', 25, 'Female'],
['Bob', 28, 'Male'],
['Cathy', 22, 'Female']
]
with open('output.csv', mode='w', newline='') as file:
writer = csv.writer(file, delimiter=';') # 指定分隔符为分号
writer.writerows(data)
# 2. 处理包含引号的数据
有些 CSV 文件中的字段可能包含引号,这时在处理时可能会出现问题。你可以指定引号的处理方式,以便正确读取包含引号的字段。
# 处理包含引号的数据
with open('file.csv', mode='r') as file:
reader = csv.reader(file, quoting=csv.QUOTE_MINIMAL) # 指定引号处理方式
for row in reader:
print(row)
# 3. 处理文件编码
在处理 CSV 文件时,特别是处理非英文字符时,确保指定文件的正确编码方式,以免出现乱码问题。
# 指定文件编码方式
with open('file.csv', mode='r', encoding='utf-8') as file:
reader = csv.reader(file)
for row in reader:
print(row)
# 4. 考虑使用 DictReader 和 DictWriter
除了 csv.reader() 和 csv.writer() 外,csv 模块还提供了 csv.DictReader() 和 csv.DictWriter(),它们可以将每一行数据作为字典进行处理,使用列标题作为字典的键。
# 使用 DictReader 读取 CSV 文件
with open('file.csv', mode='r') as file:
reader = csv.DictReader(file)
for row in reader:
print(row['Name'], row['Age'], row['Gender'])
python
# 使用 DictWriter 写入 CSV 文件
fieldnames = ['Name', 'Age', 'Gender']
data = [
{'Name': 'Alice', 'Age': 25, 'Gender': 'Female'},
{'Name': 'Bob', 'Age': 28, 'Gender': 'Male'},
{'Name': 'Cathy', 'Age': 22, 'Gender': 'Female'}
]
with open('output.csv', mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(data)
这些技巧可以帮助你更好地使用 csv 模块处理不同格式的 CSV 文件,同时避免一些常见的问题,如分隔符问题、引号处理和文件编码等。