木子空间
网址导航
(opens new window)
💻 编程笔记
💻 编程笔记
Java
Java SE
Java EE
Spring Boot
MyBatis
Swing
数据库
MySQL
前端
VuePress
JavaScript库
Bootstrap
Vue
uniapp
css库
版本控制与容器化
Git
Docker
其他
Python
ElasticSearch
Kafka
Linux
微信小程序
Node
Report
一般
📦项目合集
📑博主名片
(opens new window)
🔥远程调试🔥
(opens new window)
🎃更多玩法
🎃更多玩法
酷玩机
科学上网
(opens new window)
浏览器插件
自制视频流
好用API
免费看电视
(opens new window)
搭建内网穿透
(opens new window)
🚀滴滴作者
🚀滴滴作者
联系方式
一键私聊
(opens new window)
加QQ
(opens new window)
加微信
(opens new window)
打赏支持
(opens new window)
足迹
📗木子博客
(opens new window)
📙CSDN博客
(opens new window)
GitHub
(opens new window)
Gitee
(opens new window)
公众号《木子空间Pro》
(opens new window)
💖兴趣爱好
💖兴趣爱好
吉他(探索中)
曲谱
菜谱
#
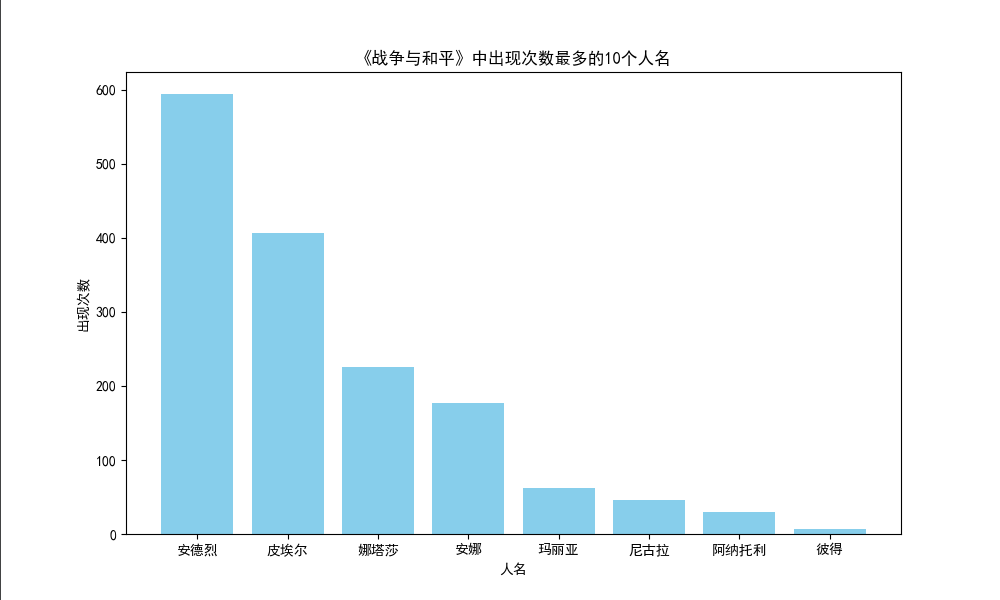
📙小说分词统计-数据可视化
#
技术栈
Python
Jieba
Matplotlib
#
要点
读取文本数据
使用 Jieba 进行中文分词
统计人名出现次数
合并别名提升准确性
绘制柱状图展示前 10 位人物出场频率
#
效果图
#
程序
点我-获取源码
←
🐞爬虫-可视化-豆瓣电影数据
🐞批量简历数据采集
→